Finetuning
Bisher sind die vortrainierten Sprachmodelle lediglich Textvervollständiger. D. h. um mit diesem
interagieren zu können, muss man die Frage in einem speziellen Format formulieren.
Frage: Wer ist der Bundeskanzler von Deutschland? Antwort:
Mit einem Finetuning und einer "Prompt"-Template kann man diese Interaktion vereinfachen und an die
spezifischen Wünsche anpassen. Doch das ist nicht der einzige Grund, ein großes Sprachmodell anzupassen.
Durch das Finetunen können noch weitere Aufgaben ermöglicht werden:
Klassifizierung: Einordnen der Texte in Spam, positive/negative
Bewertungen etc.
Zusammenfassung von Texten
Exrahieren von Informationen
Beantworten von Fragen
Suchen von semantisch ähnlichen Bedeutungen
Wir konzentrieren uns im Folgenden darauf, das Sprachmodell für Instruktionen anzupassen. Hierfür
verwenden wir den in unserem letzten Beitrag übersetzten Datensatz.
Beide Sprachmodell, die wir im Laufe des Beitrags trainieren, sind auf Huggingface veröffentlicht:
- DElefant
- DElefant-MPT
Vollständiges Finetuning
Wir können das Sprachmodell vergleichbar zum Pretraining mit dem Faust-Datensatz vollständig trainieren.
Das bedeutet, dass alle
Gewichtungen angepasst werden können. Der Nachteil hierbei besteht darin, dass auch alle Schichten,
Gradienten und der Optimizer während des Trainings geladen werden müssen. Das größte Netz, das wir
auf diese Art mit 24 GB VRAM trainieren können liegt bei 7B Parametern.
Für das Training verwenden wir ein bereits vorhandenes Repository namens Llama-X mit
einer Anpassung von WizardLM. Genauere
Informationen zum Code folgen etwas später in dem Kapitel über den Aufbau eines Trainings mit PEFT und
QLoRa Finetuning.
deepspeed Llama-X/src/train_freeform.py \
--model_name_or_path malteos/bloom-6b4-clp-german \
--data_path ger_alpaca_evol_instruct_70k_e.json \
--output_dir ./full_finetune \
--num_train_epochs 2 \
--model_max_length 2048 \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 400 \
--save_total_limit 3 \
--learning_rate 2e-5 \
--warmup_steps 2 \
--logging_steps 2 \
--lr_scheduler_type "cosine" \
--report_to "tensorboard" \
--gradient_checkpointing True \
--deepspeed deepspeed.json \
--bf16 True
Die Hyperparameter wurden vergleichbar zu dem der WizardLM Veröffentlichung gewählt. Das Training ist
hier relativ anspruchsvoll und wir benötigen die Bibliothek DeepSpeed, um das Modell überhaupt
trainieren zu können.
Mit Deepspeed können wir Teile des Netztrainings von der Grafikkarte z.B. auf die CPU verlagern, wie die
Berechnungen des Optimizers. Im Folgenden ein Auszug des Trainings, das insgesamt 50 h auf einer RTX
3090
benötigt hat.
{'loss': 0.6569, 'learning_rate': 1.2166081717612798e-11, 'epoch': 2.0}
{'loss': 0.6017, 'learning_rate': 0.0, 'epoch': 2.0}
{'train_runtime': 180191.995, 'train_samples_per_second': 0.716, 'train_steps_per_second': 0.022, 'train_loss': 0.8655412262190069, 'epoch': 2.0}
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4030/4030 [50:03:11<00:00, 44.71s/it]
`
Im linken Bild ist die Verlustfunktion des Trainings (engl. Trainings-Loss) dargestellt. Man
sieht, dass das Training stabil verläuft und der Loss stetig abnimmt. Ebenfalls gut zu erkennen
ist das Ende der ersten Epoch nach ca. 2k Trainingsschritten. Der Loss mit ca. 0.6 liegt
ebenfalls relativ gering.
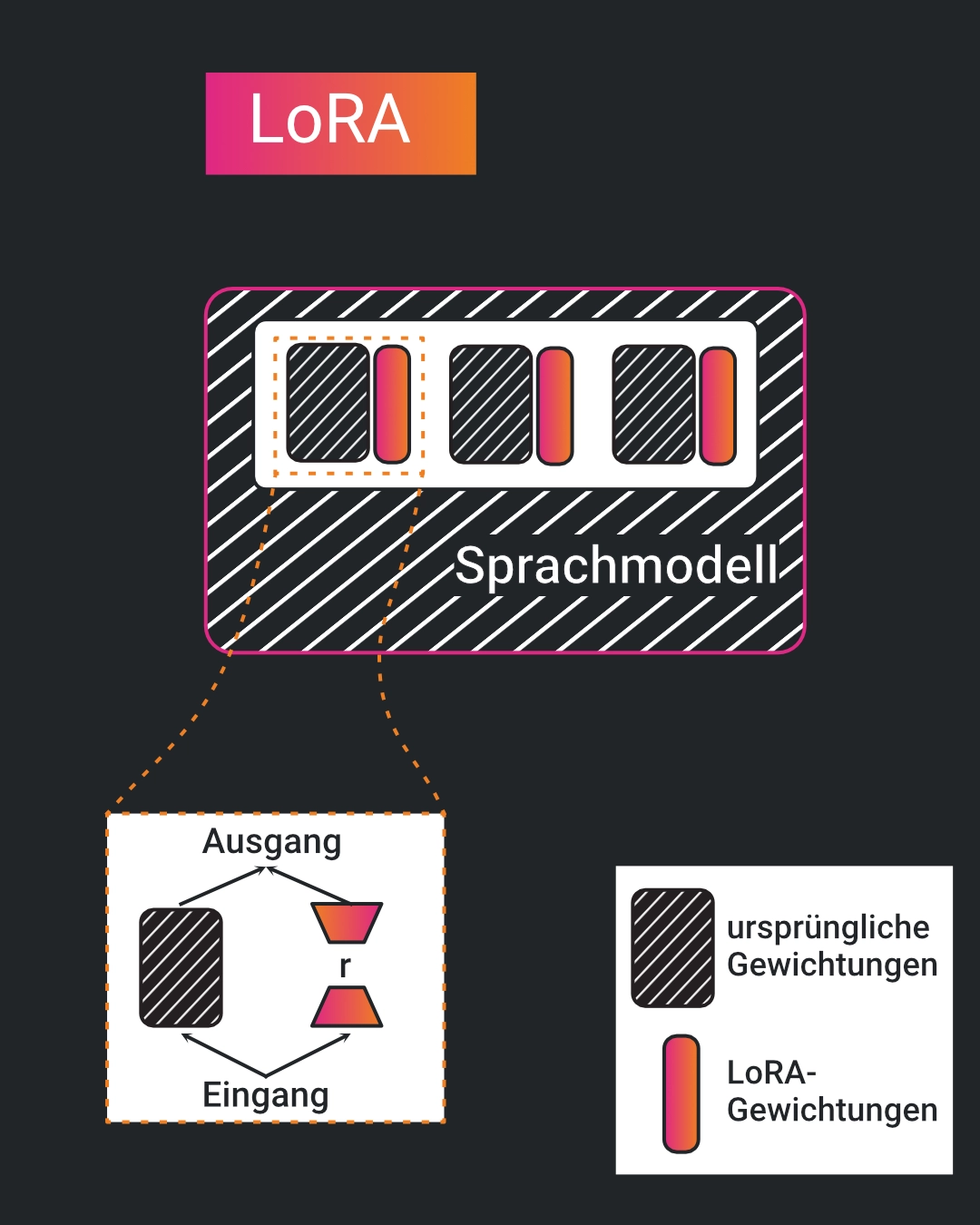
QLoRA / PEFT Finetuning
Wir müssen jedoch nicht das gesamte Modell anpassen, um ein ausreichendes Ergebnis zu erreichen.
Es reicht aus, lediglich
eine bestimmte Anzahl der Parameter anzupassen. Hierbei verwenden wir eine Funktion namens
Low-Rank Adaptation (LoRA). Die Funktionsweise
von LoRa kann dem Bild entnommen werden. Im späteren Verlauf werden wir die Bibliothek PEFT verwenden
um ein (Q)LoRa zu trainieren.
In einem weiteren Schritt wurde LoRA angepasst, um auch mit quantisierten Modellen umgehen zu
können.
Quantisierung wird verwendet, um den Rechen- und Speicherbedarfs des Modells zu reduzieren unter
Beibehaltung einer
bestimmten Genauigkeit. Hierbei die Genauigkeit der Parameter und der Aktivierung des Modells
reduziert.
Anstatt diese als 16 bit oder 64 bit floating-Werte im RAM abzulegen und zu speichern, werden in
der Regel 4 oder 8 bit Genauigkeit verwendet.
Genaueres kann dem Paper
entnommen werden.
Da das QLoRa-Finetuning nicht mehr so viel Grafikspeicher benötigt, können wir auch ein größeres
Sprachmodell
verwenden. Hierbei haben wir uns für das MPT-30B entschieden,
da andere Modelle wie Falcon-40B dennoch zu groß für den Grafikspeicher wären und die OpenLLaMA Modelle
leider
Programmcode nicht richtige interpretieren können und der übersetzte Datensatz eine Vielzahl an Code
enthält.
Weitere Herausforderungen sind, dass zum Beispiel die Funktion des LoRa-Tunings mit PEFT nicht
implementiert ist und
das "gradient accumulation" nicht funktioniert.
Bei dem Problem des PEFT-Tunings kann auf Code-Anpassungen der Community zurückgegriffen werden, die
Gradientenakkumulation
scheint jedoch noch nicht zu funktionieren. Wir haben uns deswegen dazu entschieden, zwei RTX 3090 mit
48 GB VRAM zu verwenden und
die Blocksize auf 1024 Token zu reduzieren. Das Modell kann also nicht mehr so lange Text verstehen. Was
1024
Token entspricht, kann einfach mit dem interaktiven Tokenizer untersucht werden. Damit konnten wir jedoch auch nur
eine Batchsize
von 4 erreichen, was für ein stabiles Training möglicherweise zu klein sein könnte. Trotzdem möchten
wir
untersuchen, ob ein zum Großteil auf englische Texte trainiertes Modell auf deutsche Instruktionen
angepasst werden kann.
Der Code basiert zum Großteil auf den vorher erwähnten Trainingscode LLama-X.
Wir definieren uns zuerst die gewünschten Hyperparameter sowie weitere später genutzte Variablen:
MODEL_NAME = "~/mpt_30B"
TOKENIZER_NAME = MODEL_NAME
DATA_PATH = r"ger_alpaca_evol_instruct_70k_e.json"
# Max. Modelllänge:
BLOCK_SIZE = 1024
BATCH_SIZE = 4
LR_SCHEDULER = "linear"
GR_ACCUMULATION_STEPS = 4
EPOCHS = 3
WARMUP_RATIO = 0.04
LEARNING_RATE = 2e-5
IGNORE_INDEX = -100
DEFAULT_PAD_TOKEN = "[PAD]"
DEFAULT_EOS_TOKEN = "</s>"
DEFAULT_BOS_TOKEN = "</s>"
DEFAULT_UNK_TOKEN = "</s>"
PROMPT_DICT = {
"prompt_input": (
"{instruction}\n\n### Response:"
),
"prompt_no_input": (
"{instruction}\n\n### Response:"
),
}
Hier könnten wir zum Beispiel auch die Vorlage ändern, wie die Instruktionen dem Sprachmodell zugeführt
werden. Die eigentlichen Anweisungen haben wir im ersten Schritt immer noch auf Englisch
gelassen.
Anschließend verwenden wir die BitsAndBytes Bibliothek, um das Netz mit Quantisierung zu laden. Danach
wird der
Tokenizer geladen und spezielle Tokens zum Padding u.ä. hinzugefügt. Hier definieren wir außerdem auch
die maximale
Länge, mit der das Sprachmodell umgehen kann. Je größer diese gewählt wird, desto länger können die
Zusammenhänge sein,
die erkannt werden können. Dabei wird jedoch auch mehr GPU-Speicher benötigt.
# Laden der notwendigen Biblotheken
import transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
from typing import Optional, Dict, Sequence
from transformers import BitsAndBytesConfig
# Laden der Quantisierung
nf4config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4", # Performance von NF4 besser als FP4#
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
# Laden des Tokenizers & Modells:
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, quantization_config=nf4config, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_NAME,
model_max_length=BLOCK_SIZE,
padding_side="right",
use_fast=False)
# Definieren eines Padding-Tokens:
if tokenizer.pad_token is None:
num_new_tokens = tokenizer.add_special_tokens({"pad_token": DEFAULT_PAD_TOKEN})
model.resize_token_embeddings(len(tokenizer))
input_embeddings = model.get_input_embeddings().weight.data
output_embeddings = model.get_output_embeddings().weight.data
input_embeddings_avg = input_embeddings[:-num_new_tokens].mean(dim=0, keepdim=True)
output_embeddings_avg = output_embeddings[:-num_new_tokens].mean(dim=0, keepdim=True)
input_embeddings[-num_new_tokens:] = input_embeddings_avg
output_embeddings[-num_new_tokens:] = output_embeddings_avg
if "llama" in MODEL_NAME:
tokenizer.add_special_tokens(
{
"eos_token": DEFAULT_EOS_TOKEN,
"bos_token": DEFAULT_BOS_TOKEN,
"unk_token": DEFAULT_UNK_TOKEN,
}
)
Anschließend laden wir den Datensatz über ein torch.Dataset und bereiten unsere Daten für das Training
vor, indem wir diese bereits Tokenizen.
# Definieren der Funktionen zum Erzeugen eines Datensatzes - Entnommen von Llama-X
import json
from torch.utils.data import Dataset
import torch
from dataclasses import dataclass, field
def preprocess(
sources: Sequence[str],
targets: Sequence[str],
tokenizer: transformers.PreTrainedTokenizer,
) -> Dict:
"""Preprocess the data by tokenizing."""
examples = [s + t for s, t in zip(sources, targets)]
examples_tokenized, sources_tokenized = [_tokenize_fn(strings, tokenizer) for strings in (examples, sources)]
input_ids = examples_tokenized["input_ids"]
labels = copy.deepcopy(input_ids)
for label, source_len in zip(labels, sources_tokenized["input_ids_lens"]):
label[:source_len] = IGNORE_INDEX
return dict(input_ids=input_ids, labels=labels)
class SupervisedDataset(Dataset):
"""Dataset for supervised fine-tuning."""
def __init__(self, data_path: str, tokenizer: transformers.PreTrainedTokenizer):
super(SupervisedDataset, self).__init__()
print("Loading data...")
with open(data_path, "r") as f:
list_data_dict = json.load(f)
print("Formatting inputs...")
prompt_input, prompt_no_input = PROMPT_DICT["prompt_input"], PROMPT_DICT["prompt_no_input"]
sources = [
prompt_input.format_map(example) if example.get("input", "") != "" else prompt_no_input.format_map(example)
for example in list_data_dict
]
targets = [f"{example['output']}{tokenizer.eos_token}" for example in list_data_dict]
print("Tokenizing inputs... This may take some time...")
data_dict = preprocess(sources, targets, tokenizer)
self.input_ids = data_dict["input_ids"]
self.labels = data_dict["labels"]
def __len__(self):
return len(self.input_ids)
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
return dict(input_ids=self.input_ids[i], labels=self.labels[i])
@dataclass
class DataCollatorForSupervisedDataset(object):
"""Collate examples for supervised fine-tuning."""
tokenizer: transformers.PreTrainedTokenizer
def __call__(self, instances: Sequence[Dict]) -> Dict[str, torch.Tensor]:
input_ids, labels = tuple([instance[key] for instance in instances] for key in ("input_ids", "labels"))
input_ids = torch.nn.utils.rnn.pad_sequence(
input_ids, batch_first=True, padding_value=self.tokenizer.pad_token_id
)
labels = torch.nn.utils.rnn.pad_sequence(labels, batch_first=True, padding_value=IGNORE_INDEX)
return dict(
input_ids=input_ids,
labels=labels,
attention_mask=input_ids.ne(self.tokenizer.pad_token_id),
)
# Erzeugen des eigentlichen Datensatzes:
data_module = {
"train_dataset": SupervisedDataset(tokenizer=tokenizer, data_path=DATA_PATH),
"eval_dataset": None, # Hier könnte noch ein evaluations-Datensatz verwendet werden
"data_collator": DataCollatorForSupervisedDataset(tokenizer=tokenizer),
}
Nun können wir das eigentliche Training konfigurieren. Die wichtigsten Parameter und ihr Einfluss auf das
Training:
- per_device_train_batch_size: Anzahl der Daten, die pro GPU gleichzeitig verarbeitet werden.
Begrenzt durch den Grafikspeicher.
- learning_rate: Faktor für die Anpassung der Gewichtungen.
- lr_scheduler_type: Art der Anpassung der Lernrate über der Zeit.
- num_train_epochs: Anzahl der Trainingsepochen. Bsp.: 2 Epochen bedeutet, dass das Netz die
Trainingsdaten 2x zum Training gesehen hat.
- gradient_accumulation_steps: Anzahl der Gradient Akkumulationsschritte, hiermit kann künstlich die
Batchsize künstlich erhöht werden.
# Konfigurieren der Einstellungen:
from transformers import TrainingArguments
training_args = TrainingArguments(
"./Qlora/Gerlefant",
per_device_train_batch_size=BATCH_SIZE,
lr_scheduler_type=LR_SCHEDULER,
save_strategy="no",
evaluation_strategy="steps",
logging_strategy="steps",
logging_steps=1,
save_total_limit=4,
eval_steps=None,
per_device_eval_batch_size=BATCH_SIZE,
learning_rate=LEARNING_RATE,
warmup_ratio=WARMUP_RATIO,
optim="paged_adamw_8bit", # adamw_torch
num_train_epochs=EPOCHS,
bf16=True,
max_grad_norm=0.3,
adam_beta2=0.999,
gradient_accumulation_steps=GR_ACCUMULATION_STEPS)
Anschließend müssen wir das Modell für das LoRA Training vorbereiten. Hierbei können wir die Größe der
Anpassungen definieren. Die wichtigsten Parameter sind:
- r: "Rank" der Anpassungen. Vereinfacht die Größe der Matrizen die zur Anpassung verwendet
werden: Kleine r führen zu einfacheren low-rank Matrizen, dadurch auch geringerer Anzahl an
Parametern, die für das Training verwendet werden können. Trade-Off zwischen Rechnaufwand &
mögl. Overfitting mit großen r vs. underfitting, schlechte Anpassung, geringer Rechenaufwand mit
kleinem r.
- alpha: Skalierungsfaktor, der die Höhe der Anpassung der LoRA-Adaptionen angibt. ->
höherer alpha-Wert erhöht den Einfluss, niedrigerer Wert legt mehr Gewicht auf die ursprünglichen
Verbindungen
- target_modules: Module des Modells, die angepasst werden sollen.
- lora_dropout: Wahrscheinlichkeit des Dropouts der LoRA-Module. Dropout wird zur
Regularisierung verwendet, um Overfitting zu verhindern.
Eine gute Erklärung der LoRA-Anpassung kann lightning.ai entnommen
werden.
Wir werden im Folgenden die LoRa Anpassung auf alle linearen Schichten des Modells anwenden.
model.is_parallelizable = True
model.model_parallel = True
# Prepare kbit Training:
from peft import prepare_model_for_kbit_training
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
# Anzeigen der Parameter die Trainiert werden:
def print_trainable_params(model):
t_params = 0
all_params = 0
for _,param in model.named_parameters():
all_params += param.numel()
if param.requires_grad:
t_params += param.numel()
print(f"Trainable params: {t_params} || all_params: {all_params} || trainable%: {100*t_params/all_params}")
from peft import LoraConfig, TaskType, get_peft_model
lora_config = LoraConfig(
r=64,
lora_alpha=16,
target_modules=["up_proj", "down_proj"],
lora_dropout=0.05,
inference_mode=False,
bias="none",
task_type=TaskType.CAUSAL_LM
)
model = get_peft_model(model, lora_config)
print_trainable_params(model)
Zuletzt definieren wir noch unseren Huggingface Trainer und starten das eigentliche Training.
trainer = Trainer(
model=model,
args=training_args,
tokenizer=tokenizer,
**data_module
)
# Fine-tune the model
trainer.train()
peft_model_id="./PEFT_MODEL"
trainer.model.save_pretrained(peft_model_id)
tokenizer.save_pretrained(peft_model_id)
Im linken Bild ist die Verlustfunktion des QLoRa-Trainings (engl. Trainings-Loss) dargestellt.
Im Gegensatz zum vorherigen vollständigen Finetuning sieht man deutlich stärkere Schwingungen.
Dies liegt hauptsächlich an der deutlich geringeren effektiven Batchsize von lediglich 4.
Dadurch kann das Sprachmodell unter Umständen keine Generalisierung erlernen, sondern passt sich
lediglich an diese geringen Datenpunkte an. Außerdem kann der Unterschied zwischen den Batches
deutlich größer sein. Eine größere Batchsize wäre hierbei somit hilfreich. Trotzdem kommen wir
im Mittel auf einen Trainingsloss von ca. 0.65, also in einem vergleichbaren Bereich zu dem
vorherigen vollständigen Training.
Zusammenfassung
- Vortrainierte Sprachmodelle sind bisher nur Textvervollständiger
- Finetuning ermöglicht eine Anpassung an unterschiedliche Aufgaben und Vereinfachung der Interaktion
mit dem Modell
- Vollständiges Finetuning erlaubt eine Anpassung aller Gewichtungen, aber erfordert auch das Laden
aller Schichten, Gradienten und Optimizer
- Die maximale Netzgröße beträgt damit ~7B Parameter bei 24 GB VRAM
- Effiziente Anpassung des Modells mit Low-Rank Adaptation (LoRA) möglich, um nur eine bestimmte Anzahl
der Parameter anzupassen
- QLoRa-Finetuning erlaubt die Verwendung eines größeren Sprachmodells durch Quantisierung (MPT-30B) und
benötigt weniger Grafikspeicher
- Das vollständige Finetuning benötigte ca. 50 h und das QLoRa Finetuning ca. 60 h
In unserem letzten Beitrag vergleichen wir die beiden trainierten Netze anhand von Beispielfragen mit kommerziell verfügbaren Sprachmodellen von AlephAlpha.